AWS Account Right-Sizing
Today I was attending the Microxchg 2016 conference in Berlin. I suddenly realized that going to the cloud allows to ask completely new questions that are impossible to ask in the data center.
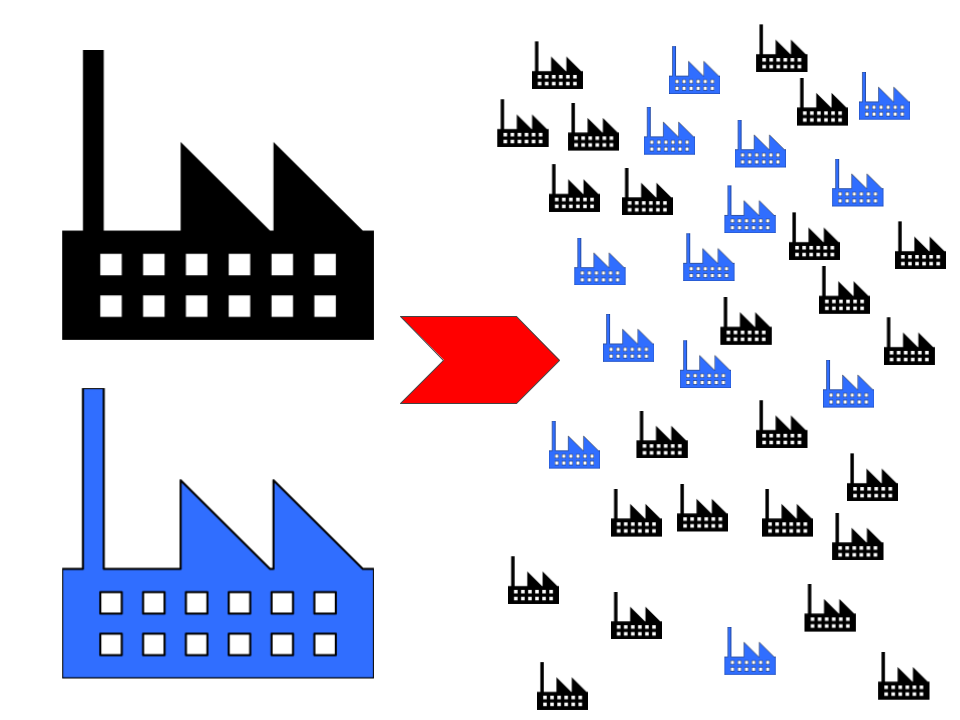
One such question is this: What is the optimum size for a data center? Microservices are all about downsizing - and in the cloud we can and should downsize the data center!
 In the world of physical data centers the question is usually goverened by two factors:
In the world of physical data centers the question is usually goverened by two factors:
One such question is this: What is the optimum size for a data center? Microservices are all about downsizing - and in the cloud we can and should downsize the data center!
- Ensuring service availability by having at least two physical data centers.
- Packing as much hardware into as little space as possible to keep the costs in check.
As long as we are smaller than the average Internet giant there is no point to ask about the optimum size. The tooling which we build has to be designed for both large data centers and for having more than one. But in the "1, 2, many" series "2" is just the worst place to be. It entails all the disadvantages of "more than 1" without any of the benefits of "many".
In the cloud the data center is purely virtual. On AWS the closest thing to a "data center" is a Virtual Private Cloud (VPC) in an AWS Region in an AWS Account. But unlike a physical data center that VPC is already highly available and offers solid redundancy through the concept Availability Zones.
If an AWS Account has multiple VPCs (either in the same region or in different regions), then we should see it has actually beeing several separate data centers. All the restrictions of multiple data centers also apply to having multiple VPCs: Higher (than local) latency, traffic costs, traversing the public Internet etc.
To understand more about the optimum size of a cloud data center we can compare three imaginary variants. I combine EC2 instances, Lambda functions, Beanstalk etc. all into "code running" resources. IMHO it does not matter how the code runs in order to estimate the management challanges involved.
Small VPC
|
Medium VPC
|
Large VPC
| |
Number of code running resources
|
50
|
200
|
1000
|
Number of CloudFormation stacks
(10 VMs per stack) |
5
|
20
|
100
|
Service Discovery
|
manually
|
simple tooling e.g. git repo with everything in it
| |
Which application is driving the costs?
|
Eyeball inspection - just look at it
|
Tagging, Netflix ICE ...
|
Complex tagging, maintain an application registry, pay for Cloudhealth ...
|
Deployment
|
CloudFormation manually operated viable option
|
Simple tooling like cfn-sphere, autostacker24 ...
|
Multi-tiered tooling like Spinnaker or other large solutions
|
Security model
|
Everyone related is admin
|
Everyone related is admin, must have strong traceability of changes
|
Probably need to have several levels of access, separation of duty and so on
|
… whatever ...
|
dumb and easy
|
simple
|
complex and complicated
|
Having a large VPC with a lot of resources obviously requires much more elaborate tooling while a small VPC can be easily managed with simple tooling. In our case we have a 1:1 relationship between a VPC and an AWS account. Accounts that work in two regions (Frankfurt and Ireland) have 2 VPCs but that's it.
I strongly believe that scaling small AWS accounts together with the engineering teams who use them will still allow us to keep going with simple tooling. Even if the absolute total of code running resources is large, splitting it into many small units reduces the local complexity and allows the responsible team to manage their area with fairly simple tooling. Here we use the power of "many" and invest into handling many AWS accounts and VPCs efficiently.
On the overarching level we can then focus on aggregated information (e.g. costs per AWS account) without bothering about the internals of each small VPC.
I therefore strongly advise to keep your data centers small. This will also nicely support an affordable Cloud Exit Strategy.


Comments
Post a Comment